* 대표적인 예측 분류 기준
- 주관적 혹은 객관적
- 정성적 혹은 정량적
- 시계열 혹은 인과관계
- 측정 혹은 시뮬레이션
- 분류는 절대적이지 않음 : 한 예측(방법)이 여러 특성 지닐 수 있음.
* 가장 흔한 분류
- 주관적 예측
- 객관적 예측 : 시계열 모델, 인과 관계 모델
* 주관적 예측 방법
- 주관적 예측 : 주관적 예측은 수학적 통계적 방법보다 인간의(때로는 직관적인)판단, 의견, 경험을 많이 반영
- 데이터 가용성이 제한적 일 때 사용됨
* 주관적 예측의 대표적인 방법들
1) 판매 합성 지표
각 영업 사원(고객을 잘 이해한다고 생각되는 사람들)이 예측 정보를 제공하며, 이 정보들을 상위 조직에서 종합해가며 전체 지표 예측
장점 : 수치로 표현되기 힘든 현장 정보 반영
단점 : 지나치게 낙관적 일 수 있음
2) 고객 설문 조사(시장 조사)
고객에게 의견, 구매 계획 등을 묻는 방법
다양하고 정교하고 효과적인 방법이 존재
흔한 어려움
1) 소비자가 대답하기 어려운 질문 존재
2) 소비자가 원하는 것이 실제로 구매하는 것과 다를 수 있음
3) 소비자는 자신이 무엇을 원하는지 모를 수 있음
3) 배심원(패널)토론
- 전문가 그룹이 함께 작업하고 예측 도출
- 전문가의 경험/의견을 통계적 방법과 결합 가능
- 전문가 의견 수렴 후 신속히 결과 도출 가능
- '집단 사고'의 장.단점
: 장점으로는 일반적으로 전문가 의견 신뢰 가능
: 단점으로는 배심원 중 소수가 전체 의견 지배 가능
4) 델파이 방법
- 전문가 의견 수집 및 제시 반복하여 수행, 조사 주관자가 (합의가 이루어질 때가지) 여러 번 수행.
- 참가자 정보를 전문가 상호간 밝히지 않고, 전문가 간의 개인적인 상호 작용 배제.
장점 : 객관성 보장
단점 : 전문가 의견이 조사자 질문에 영향 받음
* 유추의 사용
- 예측을 위해 유사한 사례를 활용
- 새로운 제품이나 상황에 사용 가능
- 적당한 참고 사례 존재하지 않을 수 있음
* 객관적 예측 방법
: (정량적인) 데이터 분석 기반
: 수학적, 확률적, 통계적 모델 활용
* 객관적 예측 방법의 구분
- 외삽법(시계열 방법 포함) : 시간 지표와 예측할 변수의 과거 값 사용
영향 (원인-결과) 혹은 상관관계 모델 : 예측할 변수와 관련된 다른 변수(시간이 아님)의 관계 도출
목표 : (시계열 변수의)과거 데이터에서 패턴을 식별하고 예측할 미래 구간으로 패턴을 외삽(확장)하는 것
예측할 변수 자체의 과거 값만 사용, 다른 정보 활용하지 않음
다른 명칭 : 순진한 방법, 시계열 방법
ex) 추세 기반 회귀 분석, 이동 평균, 지수 평활화, 자기 회귀
* 시계열 모델의 일반적 형태

* 인과 관계 모델의 일반적 형태
* 선형 회귀 분석 모델
- 인과관계 분석에 많이 활용되는 모형의 특별한 경우로, 예측 변수와 설명 변수 사이의 선형 관계 가정
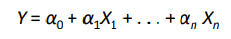
- 상수 A0,....An의 평가(값을 구하는 것)가 예측 과정의 주요한 과제임. 최소제곱법 등이 활용됨
- 가장 흔히 사용되는 모형
- 다른 명칭 : 계량 경제 모델
- 시간을 독립 변수로 하여, 시계열 분석에도 사용 가능
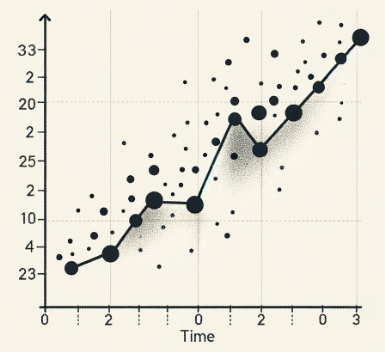
* 예측 모델 패턴의 구성 요소
- 데이터 기반 예측에서 흔히 나타나는 형태
1) 임의성 또는 잡음(구조/규칙 포함)
2) 추세 : 성장 / 감소;선형/비선형
3) 비선형 형식 : 지수, S, 점근선 등
4) 계절성 : 일정한 간격으로 반복
5) 사이클 : 다양한 길이와 크기로 반복
6) 자기 상관 : 과거 값과의 상관 관계
ex) 패턴 예 : 임의성

ex) 패턴 예 : 선형 증가
ex) 패턴 예 : 비선형 증가
ex) 패턴 예 : 계절성
ex) 패턴 예 : 무작위성, 선형 추세, 계절성 중첩
* 예측에 대한 평가
- 예측 오차
예측 오차는 예측된 값과 실제로 관찰된 값의 차이로 표현
Dt - Ft or Ft - Dt로 계산되며, 정의가 일관되기만 하면 됨
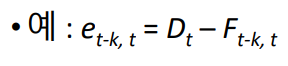
* 예측 정확도 측정 지표
- 평균 절대 편차 (MAD):

- 평균 절대 비율 오류 (MAPE):
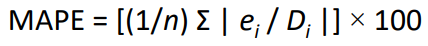
- 평균 자승 오차 (MSE):
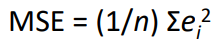
- 루트 평균 제곱 오류(RMSE):

* 예측 정확도 측정 지표 예
- 시간 : t = 1,2,3,4,5,6
- 지금까지 관찰된 데이터
D1 = 9, D2 = 7, D3 = 11, D4 = 11, D5 = 9, D6 = 10
- 지금까지 수행한 예측
F1= 11, F2 = 6, F3 = 10, F4 = 12, F5 = 7, F6 = 13
- RMSE
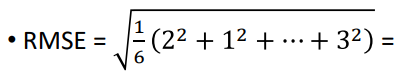
* 예측 편향
- 편향되지 않은 예측의 특성
- 일반적으로 오차의 기대치 E[ei] = 0
- 특별한 오류 패턴이 없다.
오류에 패턴이 있으면 이 패턴을 보정한 부분이 예측 모델에 포함될 수 있다.
* 편향된 예측
- 편향된 예측의 특징
예측 오차의 평균값이 0이 아니다.
오차에 패턴이 있다.
- 미편향/편향된 예측의 예

* 예측 모니터링 및 조정
예측에서는 예측이 실제 시스템을 얼마나 잘 예측하고 있는지 모니터링한다. 따라서, 흔히 적응형 예측이 사용된다. 즉 예측 오류를 모니터링하고 예측 매개 변수를 조정하여 예측 오류를 지속적으로 최소화 한다.
* 예측 평가의 복잡성
다양한 평가 기준과 지표 존재
- 예측 오차를 어떻게 설정할 것인가?
- 예측이 맞았다는 것을 어떻게 정의할 것인가?
* 예측에서의 평활화
평활화는 우리의 예측이 장기 추세를 더 분명하게 보여주는 것을 가능하게 한다.
모든 프로세스(예 : 시계열)에는 고유한 임의 변동이 있다.
우리는 장기적인 장기 추세가 더 명확하게 예측에서 드러나기를 원하며 동시에 단기간의 무작위 변동은 예측에서 완만하게(상쇄되어) 표현되기를 원한다.
'생산운영관리' 카테고리의 다른 글
| [생산운영관리] 계절성이 있는 수요 분석 (0) | 2024.05.04 |
|---|---|
| [생산운영관리] 추세 고려하는 예측 방법(회귀 분석, 이중 지수 평활법) (0) | 2024.04.28 |
| [생산운영관리] 시계열분석, 이동평균법, 가중이동평균법, 지수평활법 (1) | 2024.04.27 |
| [생산운영관리] 예측, 수요예측에 대하여 (1) | 2024.04.27 |
| [생산운영관리] 생산운영관리의 의사결정 (0) | 2024.03.18 |



