안녕하세요! 오늘은 MINST DATA로 RBM 학습시키는 프로그램을 만들어 보고자 합니다.
방법은 오픈소스와 Chat GPT를 이용해서 만들었습니다.
1. 오픈소스 출처 : https://github.com/mr-easy/Restricted-Boltzmann-Machine
GitHub - mr-easy/Restricted-Boltzmann-Machine: Python implementation of Restricted Boltzmann Machine (RBM). And an example on MN
Python implementation of Restricted Boltzmann Machine (RBM). And an example on MNIST dataset. - mr-easy/Restricted-Boltzmann-Machine
github.com
2. 코드 리뷰

먼저 필요한 라이브러리를 설치 합니다.

IDX 파일 형식으로 저장된 데이터(예를 들어 MNIST 데이터셋)를 읽어들이는 Python 함수 read_idx를 정의하는 내용입니다. IDX 파일 형식은 머신러닝 데이터셋을 위해 사용됩니다.

MNIST 데이터세트를 로드하고 전처리합니다. 사용자 정의 함수를 사용하여 이미지와 라벨 데이터를 읽고, 모델 입력 호환성을 위해 이미지 데이터를 재구성하고, 픽셀 값을 0-255에서 0-1로 정규화하여 더 빠르고 효과적인 학습을 위해 진행 합니다.

MNIST 데이터세트의 이미지 데이터가 포함된 'X' 배열에서 특정 이미지를 선택합니다. Python의 인덱싱을 사용하여 배열 내의 특정 위치에 있는 이미지를 선택합니다. 인덱스 '[1, 6, 5, 12, 26, 35, 62, 52, 46, 4]'는 선택한 이미지가 저장된 데이터 세트의 위치를 나타냅니다.
- 분할 비율 설정: split 변수는 0.1로 설정됩니다. 즉, 데이터 세트의 10%가 검증에 사용되고 나머지 90%는 훈련에 사용됩니다.
- 인덱스 섞기: 데이터 세트 항목에 해당하는 인덱스 배열을 생성하고 이를 섞어 기차 검증 분할의 무작위성을 보장함으로써 일반화를 촉진하고 원래 데이터 순서로 인해 발생할 수 있는 편향을 방지합니다.
- 검증 세트 생성: 'X_val' 및 'y_val'은 각각 'X' 및 'y'에서 섞인 인덱스의 처음 10%를 가져와 생성됩니다. 이러한 조각은 검증 세트의 기능과 레이블을 나타냅니다.
- 트레이닝 세트 생성: 'X_train' 및 'y_train'은 검증 세트 이후의 나머지 90% 데이터를 가져와 생성됩니다. 이는 훈련 세트의 기능과 레이블을 나타냅니다.
- 출력 정보: 마지막으로 스크립트는 훈련 세트, 검증 세트 및 테스트 세트의 인스턴스 수를 인쇄합니다('y_test'가 사전 정의된 것으로 가정되므로 분할의 영향을 받지 않음).
1. get_batches 함수
매개변수 설정 후 셔플링을 하여 데이터를 일괄생성하는 기능입니다.
2. plot_images 함수
- 기능: 이 기능은 시각화를 위해 matplotlib를 사용하여 원본 이미지와 재구성된 이미지를 두 행으로 배열합니다. 배치의 각 이미지는 첫 번째 행에 표시되고 RBM에 의한 해당 재구성은 두 번째 행에 표시됩니다. 그런 다음 플롯을 저장하고 표시합니다.
3. plot_weights 함수
- 기능: 이 함수는 10x10 그리드의 서브플롯을 생성합니다. 여기서 각 서브플롯은 입력 이미지 크기(28x28, MNIST 가정)로 재구성된 하나의 숨겨진 단위의 가중치를 나타냅니다. 각 서브플롯은 가중치를 이미지로 표시하여 각 숨겨진 유닛이 입력 데이터에서 "초점을 맞추거나" "감지"하는 대상을 시각적으로 표현합니다. 플롯을 저장하고 표시하는 것으로 마무리됩니다.
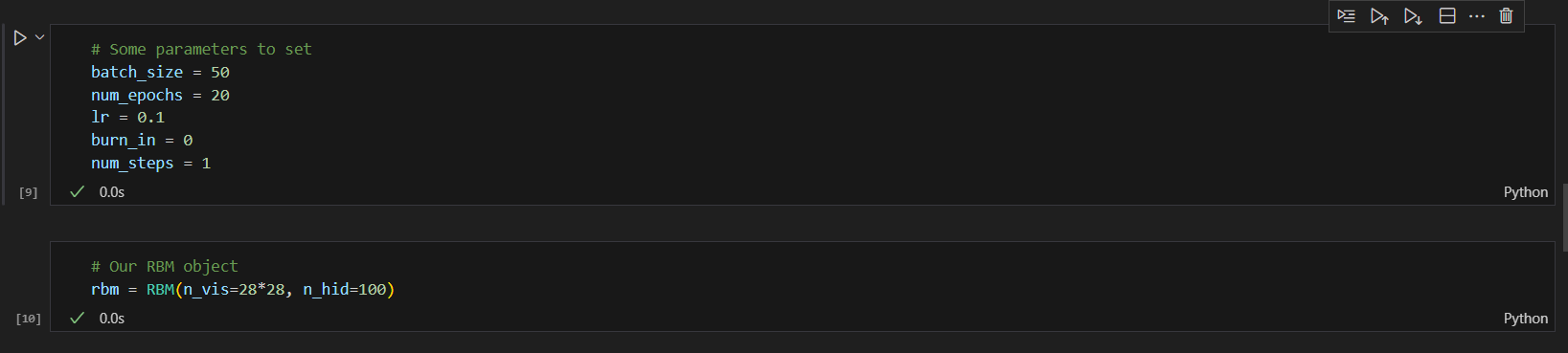
매개변수 설정 및 RBM 개체 초기화
- n_vis=28*28: 이는 표시되는 단위 수를 784로 설정합니다. 이는 일반적인 MNIST 데이터 세트 형식인 28x28 픽셀 이미지의 평면화된 치수에 해당합니다.
- n_hid=100: 숨겨진 단위 수를 100으로 설정하여 RBM이 입력 데이터의 필수 측면을 캡처하는 방법을 학습할 100개의 기능 또는 숨겨진 변수를 갖도록 구성합니다.
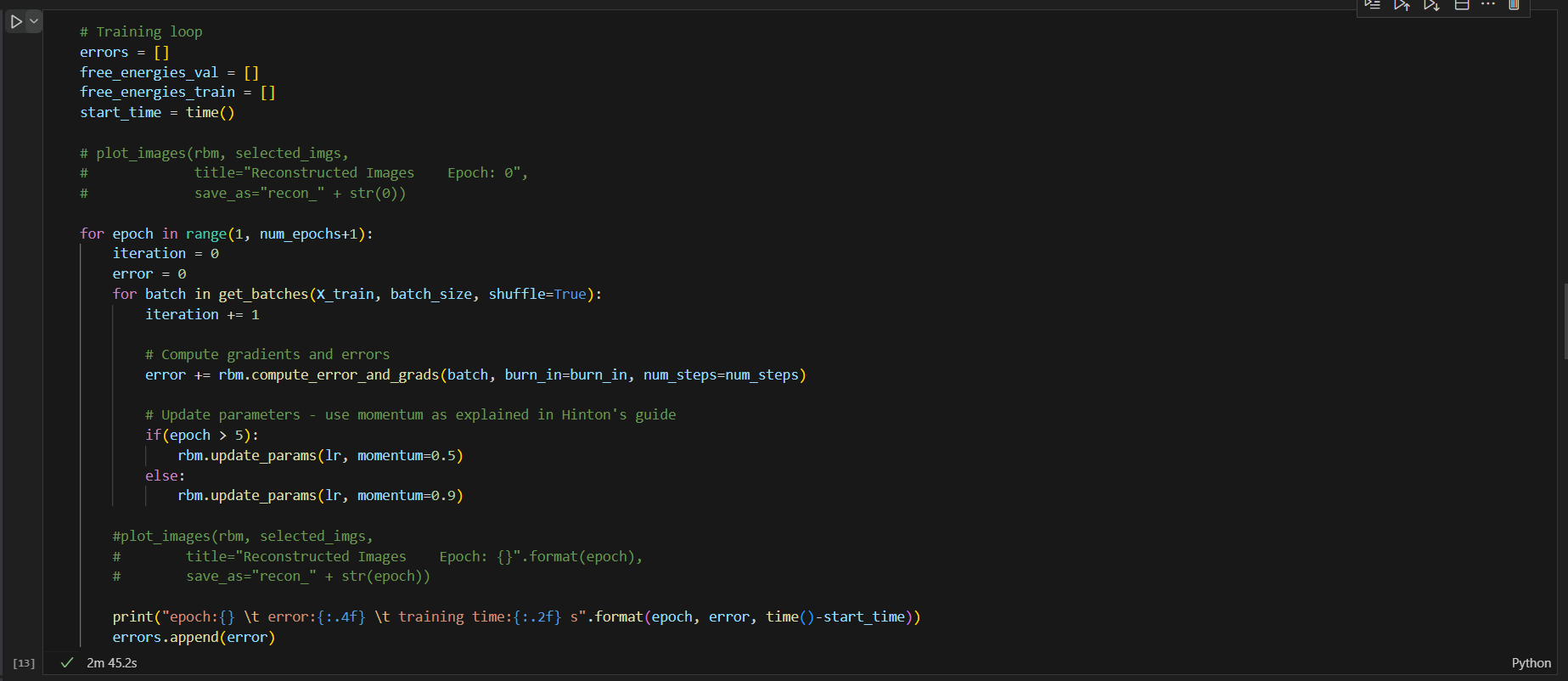
초기화
- 변수: errors, free_energies_val 및 free_energies_train은 훈련 성능 측정항목을 추적하기 위해 초기화됩니다.
- 타이밍: start_time은 훈련이 시작되는 시간을 캡처하여 훈련 프로세스 기간을 모니터링합니다.
훈련 루프
- 루프는 지정된 에포크 수(num_epochs) 동안 실행됩니다. 각 시대는 전체 데이터 세트를 일괄 처리합니다.
일괄 처리
- 데이터 셔플링 및 일괄 처리: 'get_batches' 함수는 데이터 셔플 옵션과 함께 호출됩니다. 이 함수는 훈련 데이터(X_train)를 지정된 크기(batch_size)의 배치로 나눕니다.
오류 계산 및 매개변수 업데이트
- 오류 및 기울기: 각 배치 내에서 RBM은 학습에 필요한 오류와 기울기를 계산합니다. 'compute_error_and_grads' 메서드가 호출되는데, 여기에는 입력을 재구성하기 위한 순방향 전달을 수행하고, 손실(오류)을 계산한 다음, 역전파 또는 대조 발산을 통해 기울기를 계산하는 작업이 포함될 수 있습니다(구체적인 방법은 RBM 구현 세부 사항에 따라 다름).
- 매개변수 업데이트: RBM의 매개변수는 모멘텀 기반 최적화 접근 방식을 사용하여 업데이트됩니다. 모멘텀은 경사 벡터를 올바른 방향으로 가속화하여 수렴 속도를 높이는 데 도움이 됩니다. 초기 에포크에서는 로컬 최소값을 벗어나기 위해 모멘텀이 더 높고(0.9), 업데이트를 안정화하기 위해 5번째 에포크 이후에는 모멘텀이 감소합니다(0.5).
모니터링 및 플로팅
- 에포크 완료: 각 에포크가 끝나면 훈련 오류와 훈련 시작 이후 경과 시간이 인쇄됩니다. 현재 에포크의 오류는 향후 분석을 위해 '오류' 목록에 추가됩니다.
- 이미지 재구성: (주석 처리됨) 처음에는 RBM이 훈련을 통해 선택된 입력 이미지를 얼마나 잘 재구성하는지 시각화하는 'plot_images' 함수를 사용하여 시작 시와 각 시대 이후에 재구성된 이미지를 플롯하기 위한 것입니다. 이 기능은 현재 주석 처리되어 있습니다. 아마도 훈련 과정의 속도를 높이거나 매 에포크의 시각화가 필요하지 않기 때문일 것입니다.


나머지는 시각화를 하는 코드입니다.
3. 결과
러닝 1회차 경우의 에러수준을 확인 해보았습니다.

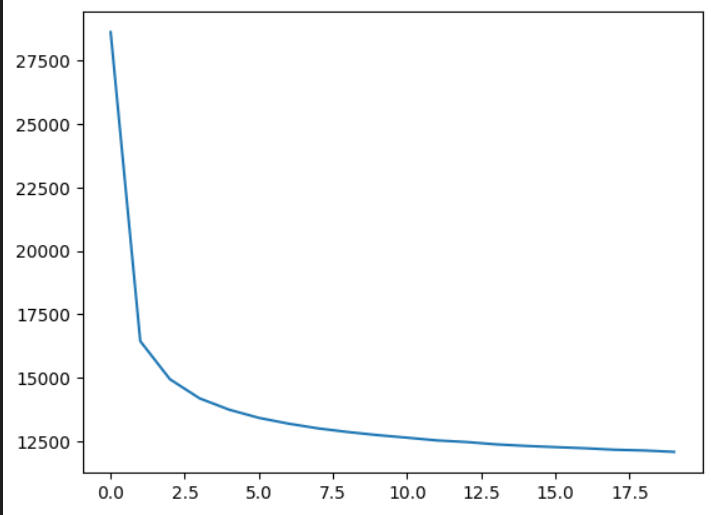
특히, 그래프로 확인 해보았을 때 2회차 부터 급격하게 에러 수준이 떨어지는 것이 보입니다.
러닝 2회차는 MINST DATA를 셔플하는 하는 함수를 썼기 때문에 새로운 이미지를 넣은 것과 동일하다고 생각이듭니다.
과연 결과가 어떻게 나올지 보겠습니다.
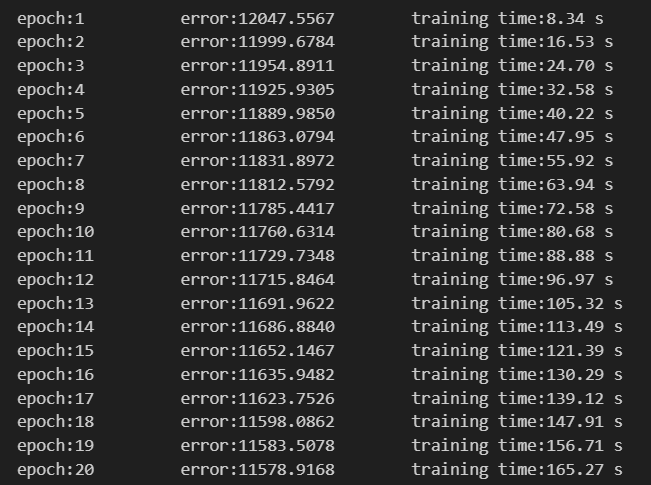
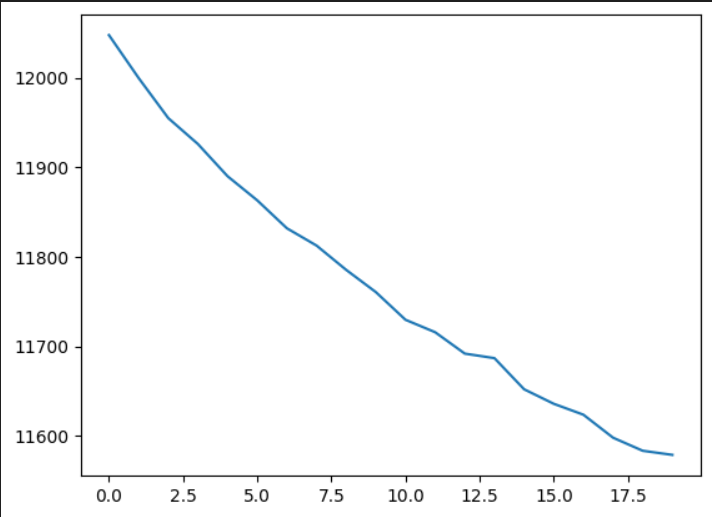
2회차도 1차 함수의 형태처럼 떨어지는 추세지만 스케일을 보았을 때는 1차보다 낮아졌음을 확인 하였습니다.
결국 3~N회차로 갈수록 Saturation 될것이 예상됩니다.
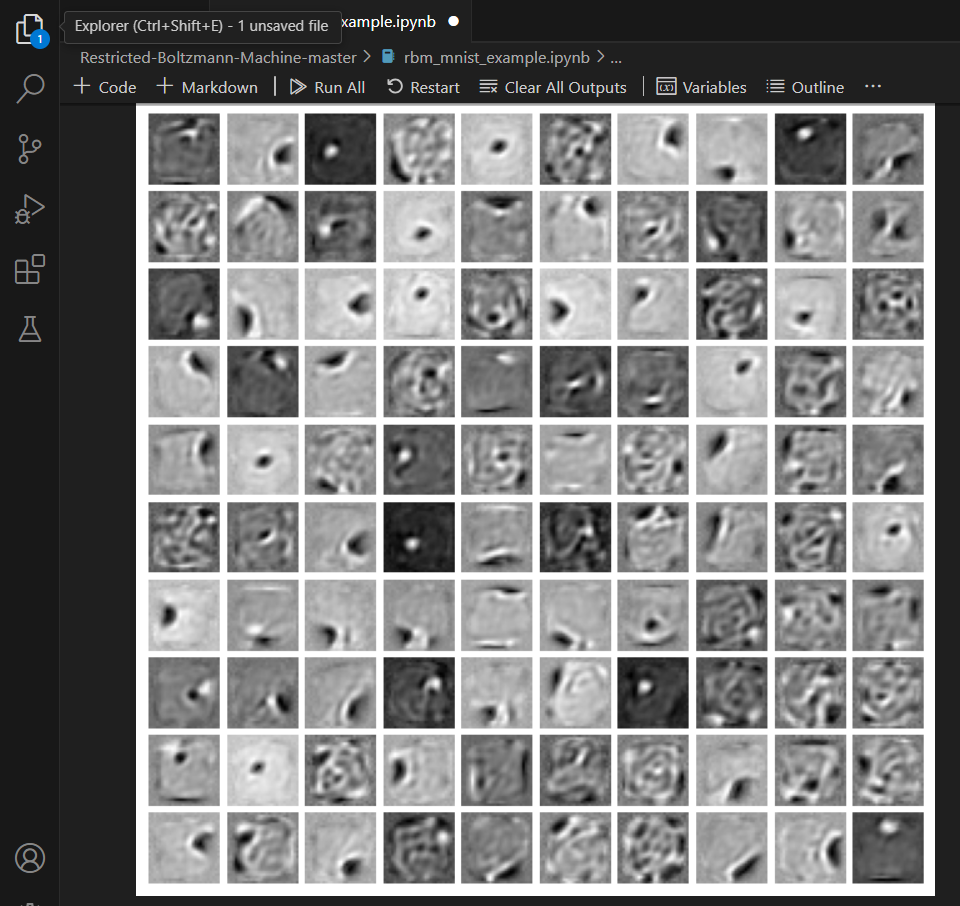

오리지널 데이타와 재구조화된 이미지가 거의 해상도의 차이만 있을뿐 형태는 동일하게 보임이 확인 됩니다.
* 어려운점 :
RBM 훈련의 융합 문제
- 문제: RBM은 잘못된 매개변수 초기화 또는 부적절한 학습 속도 선택과 같은 문제로 인해 효과적으로 훈련하기 까다로울 수 있으며, 이로 인해 수렴 속도가 느려지거나 로컬 최소값에 갇힐 수 있습니다.
- 해결한 방안:
- 매개변수 초기화: 표준 편차(예: 0.01)가 작은 가우스 분포에서 가중치를 초기화했습니다.
- 학습률 조정: 시간이 지남에 따라 학습률을 낮추는 학습률 일정을 구현하였습니다.
- 모멘텀 사용: 학습 프로세스에 모멘텀을 추가하면 올바른 방향으로 기울기를 가속화하여 수렴을 향상시키는 데 도움이 되었습니다.
그리고 추가적으로 오픈소스를 참고해서 순수 GPT로만 제가 만든 코드도 구현해 보았습니다.
저랑 GPT가 만든 코드는 러닝시간이 좀더 오픈 소스보다 길어 속도 측면에서 단점으로 생각합니다.
어떤 차이가 있고 장단점이 있는지 댓글에 달아주시면 좋을꺼 같습니다.
감사합니다!
'인공지능' 카테고리의 다른 글
| [인공지능] 로봇 계획의 사례와 알고리즘 구현 (0) | 2024.05.28 |
|---|---|
| [인공지능] Q-learning으로 로봇의 경로찾기 (0) | 2024.05.28 |
| [인공지능] Informed Search (0) | 2024.04.10 |
| [인공지능] Uninformed Search (0) | 2024.04.10 |
| [인공지능] 인공지능이란 무엇인가? (0) | 2024.04.10 |



