* 게임 트리(game tree)
• 상대가 있는 게임, 자신과 상대방의 가능한 게임 상태를 나타낸 트리
• 예: 틱-택-톡(tic-tac-toc), 바둑, 장기, 체스 등
• 게임의 결과는 마지막에 결정
• 많은 수(lookahead)를 볼 수록 유리
* Mini-max algorithm (player1, player2)
• player1: MAX 노드
-> 자신에 해당하는 노드로 자기에게 유리한 최대값 선택
• player2: MIN 노드
-> 상대방에 해당하는 노드로 최소값 선택
• 단말 노드부터 위로 올라가면서 최소(minimum)-최대(maximum) 연산을 반복하여 자신이 선택할 수 있는 방법 중 가장 좋은 것은 값을 결정
* α-β 가지치기 (prunning)
• 검토할 필요가 없는 부분을 탐색하지 않도록 하는 기법
• 깊이 우선 탐색 (DFS)으로 제한 깊이까지 탐색을 하면서, MAX 노드 와 MIN 노드의 값 결정
• α-자르기(cut-off) : MIN 노드의 현재값이 부모노드의 현재 값보다 작거나 같으면, 나머지 자식 노드 탐색 중
• β-자르기 : MAX 노드의 현재값이 부모노드의 현재 값보다 같거나 크면, 나머지 자식 노드 탐색 중지
* 몬테카를로 시뮬레이션
• 특정 확률 분포로부터 무작위 표본(random sample)을 생성
• 이 표본에 따라 행동 과정을 반복, 결과를 확인
-> 이러한 결과 확인 과정을 반복하여 최종 결정을 하는 것
예: 원주율 (𝜋) 구하기, 바둑 게임
* 몬테카를로 트리 탐색
- 탐색 공간(search space)을 무작위 표본추출(random sampling)을 하면서, 탐색트리를 확장하여 가장 좋아 보이는 것을 선택하는 휴리스틱 탐색 방법
- Best-first search 알고리즘 기반, Heuristic이 아닌 simulation으로 탐색이 차이점이다.
- 각 노드는 두가지 변수로 구성되어 있다.
1) 시뮬레이션 게임의 결과 노드를 방문한 횟수의 평균
2) 방문 횟수
- 4단계: 선택 -> 확장 -> 시뮬레이션 -> 역전파
- 동작 선택 방법
• 가장 승률이 높은, 루트의 자식 노드 선택
• 가장 빈번하게 방문한, 루트의 자식 노드 선택
• 승률과 빈도가 가장 큰, 루트의 자식 노드 선택 없으면, 조건을 만족하는 것이 나올 때까지 탐색 반복
• 자식 노드의 confidence bound(신뢰 구간)값의 최소값이 가장 큰, 루트의 자식 노드 선택
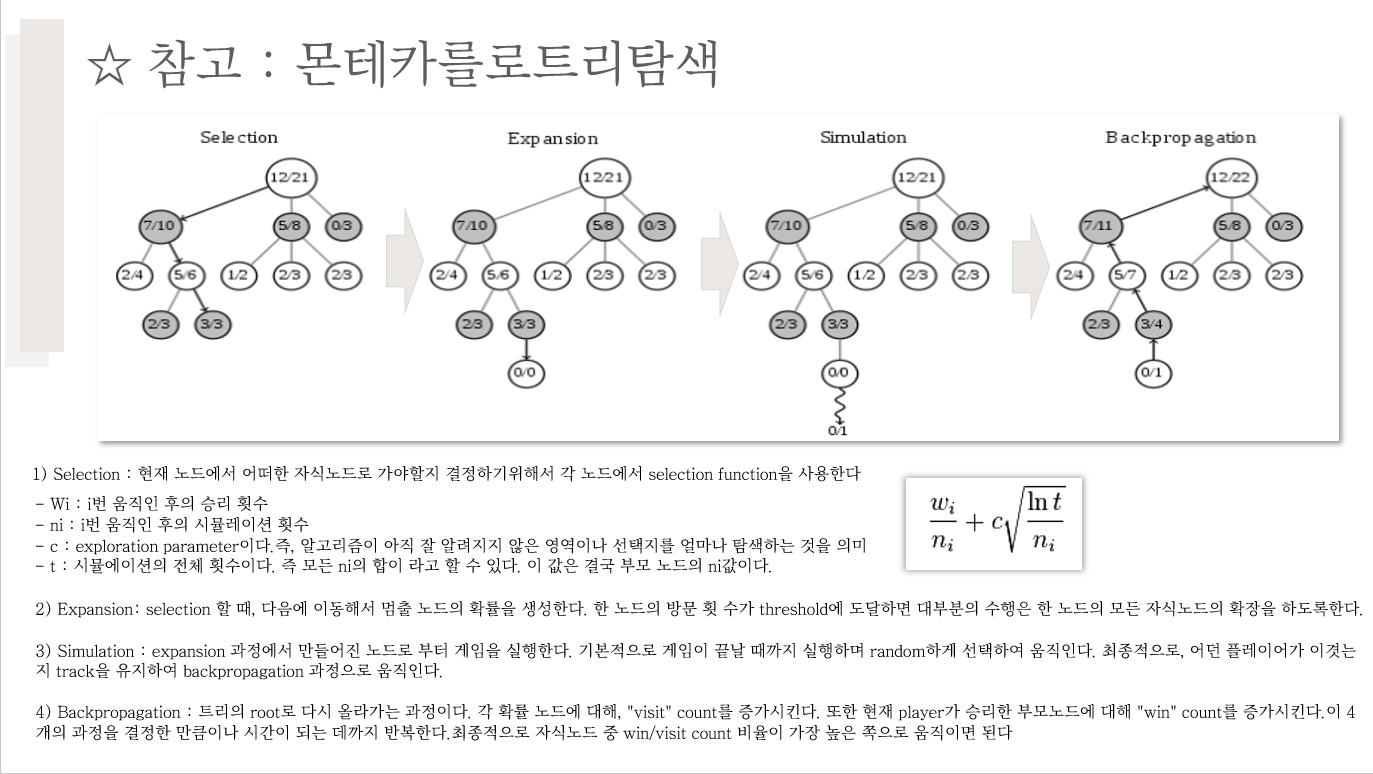
* 선택(selection) : 트리 정책(tree policy) 적용
• 루트노드에서 시작
• 정책에 따라 자식 노드를 선택하여 단말노드까지 내려 감
• 승률과 노드 방문횟수 고려하여 선택
• UCB(Upper Confidence Bound) 정책 : UCB가 큰 것 선택

* 확장(expansion)
• 단말노드에서 트리 정책에 따라 노드 추가
• 예) 일정 횟수이상 시도된 수(move)가 있으면 해당 수에 대한 노드 추가
* 시뮬레이션(simulation)
• 기본 정책(default policy)에 의한 몬테카를로 시뮬레이션 적용
• 무작위 선택(random moves)으로 게임 끝날 때까지 진행
* 역전파(backpropagation)
• 단말 노드에서 루트 노드까지 올라가면서 승점 반영
'인공지능' 카테고리의 다른 글
| [인공지능] Uninformed Search (0) | 2024.04.10 |
|---|---|
| [인공지능] 인공지능이란 무엇인가? (0) | 2024.04.10 |
| [인공지능] 인공지능 탐색에 대한 나의 고찰 (0) | 2024.03.24 |
| [인공지능] Chat GPT 왕초보도 할 수 있다!(개념, 사용법) (2) | 2024.03.19 |
| [인공지능] 인공지능의 역사와 기술,활용 (2) | 2024.03.15 |



