728x90
반응형
1. CNN이란?
이미지 인식에 특화된 딥러닝 모델
일반 DNN은 이미지의 공간 구조를 무시하고 1차원으로 펼침
→ 위치 정보 손실, 파라미터 수 증가
CNN은 위치, 모양, 패턴을 잘 포착함
2. CNN의 생물학적 배경
- Hubel & Wiesel (1959): 고양이 시각 피질 실험 → 계층 구조로 시각 자극을 처리하는 뉴런 발견
- Kunihiko Fukushima: Neocognitron 제안
- Yann LeCun: LeNet-5 → 최초의 CNN 모델
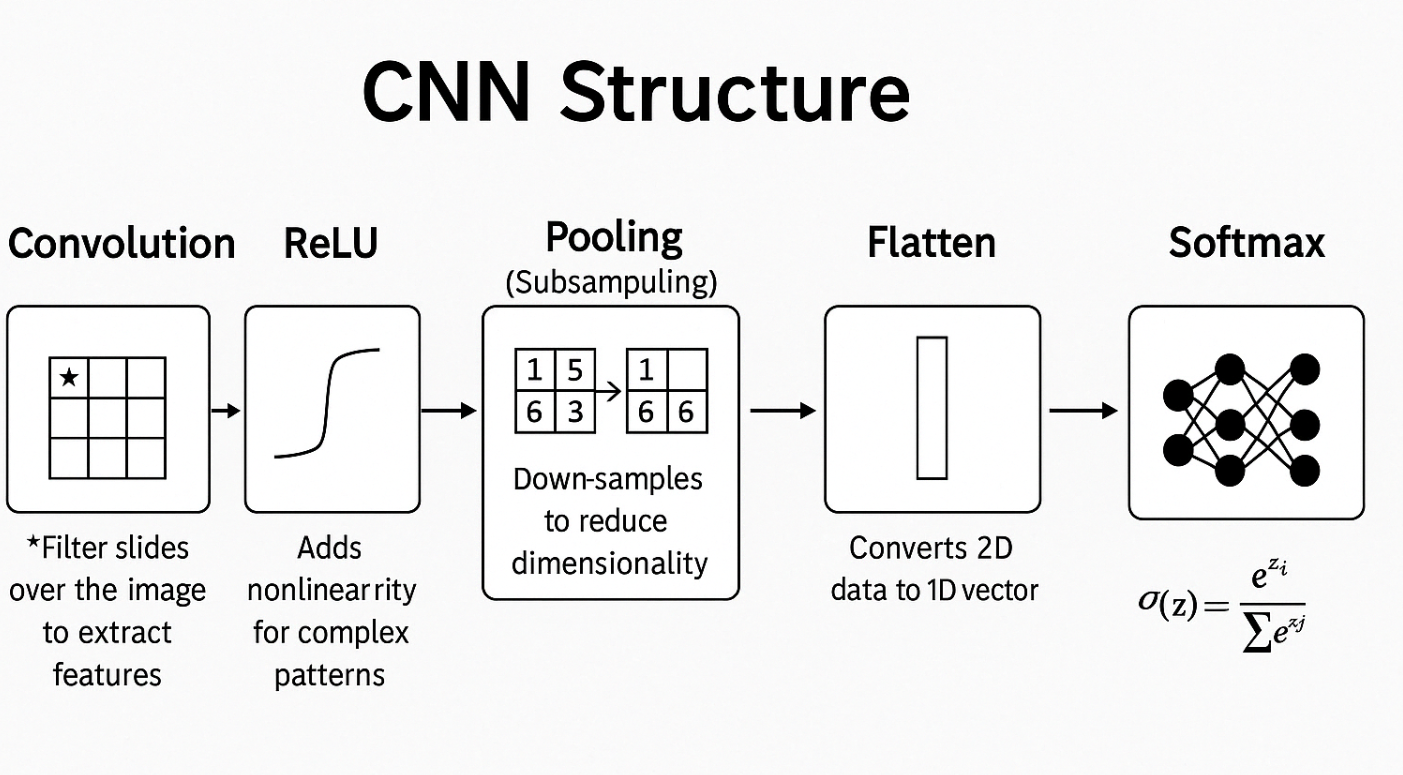
3. CNN 핵심 구조
입력 → Convolution → ReLU → Pooling → Flatten → FC Layer → Softmax
🔹 Convolution 연산
- 필터(커널)를 이미지에 슬라이딩하며 특징 추출
- 실제 CNN에서는 cross-correlation 사용
- 결과는 Feature map / Activation map이라고 부름
🔹 Activation Function (활성화 함수)
- 주로 ReLU 사용: 음수 → 0, 양수는 그대로
- 비선형성 추가 → 복잡한 패턴 학습 가능
🔹 Pooling (Subsampling)
- 이미지 크기를 줄이면서 특징은 유지
- 종류:
- Max Pooling: 가장 큰 값
- Average Pooling: 평균
- 장점: 연산량 감소, 과적합 감소, 위치 불변성
4. CNN에서의 입력 & 필터 형태
- 이미지: 3차원 텐서 (W × H × C)
예: 32×32×3 (RGB 이미지)
- 필터: 3차원 (W × H × D), 깊이 D는 입력과 동일
→ 여러 개의 필터 사용 → 여러 개의 Feature map 생성
5. Stride & Padding
| Stride | 필터가 이동하는 간격 (1 이상) |
| Padding | 경계에 0 추가하여 출력 크기 조절 |
| 출력 크기 공식 |  |
6. CNN의 핵심 특징
| 특징 | 설명 |
| Local connectivity | 일부만 연결되어 학습 효율↑ |
| Weight sharing | 같은 필터를 반복 사용 → 파라미터↓ |
| Pooling | 차원 축소 + 위치 변화에 강함 |
7. 개선된 CNN 모델 구조
| 모델 | 특징 |
| VGGNet | 3×3 필터 반복 → 단순하고 깊은 구조 |
| GoogLeNet | 다양한 필터를 병렬 사용 (Inception module) |
| ResNet | Skip connection 사용 → gradient vanishing 방지 |
| MobileNet | 경량화된 구조, Depthwise Separable Conv 사용 |
| Vision Transformer | CNN 대신 Attention 사용 |
8. CNN 학습 과정 요약
- 이미지 입력 (예: 32×32×3)
- Convolution → Feature map 추출
- ReLU → 비선형성
- Pooling → 크기 축소
- Flatten → 1D 벡터
- Fully Connected → 최종 분류
- Softmax → 확률 출력
728x90
반응형
'딥러닝' 카테고리의 다른 글
| [딥러닝] 딥러닝 모델의 초기화와 정규화 기법 (0) | 2025.06.01 |
|---|---|
| [딥러닝] 딥러닝 기반 시각 인식 모델: CNN 구조 및 활용 (0) | 2025.05.17 |
| [딥러닝] DNN 학습의 원리와 최적화 전략 (0) | 2025.04.20 |
| [딥러닝] 딥러닝 모델은 어떻게 학습되는가? – DNN & CNN 학습 구조 (1) | 2025.04.20 |
| [딥러닝] DNN 설계에 관한 핵심 내용들 (0) | 2025.04.14 |



