* 데이터 베이스 : 사용자의 실 세계를 사용자의 요구에 맞게 컴퓨터에 형상화한 서로 관계가 있는 데이터의 모임
* 데이터 공유란? : 한 데이터를 응용프로그램이 현 데이터를 같이 사용하는 것
데이터 중복 제어 : 데이터 공유가 가능하면 중복을 완전히 없앨 수 있다.
-> 중복의 가장 큰 문제 : Inconsistency(불일치) 문제 // 기존에 같은 데이터가 수정.추가 작업을 거칠 시 달라지는 문제
데이터 중복제어가 필요한 이유 : 중요한 데이터를 한곳에 두면 훼손 혹은 손실이 발생할 우려가 있음, 그 데이터는 중복을 허용
데이터 독립(Independence) : 데이터 종속과는 반대되는 개념,
한 데이터가 여러 응용프로그램에서 사용 가능 한 경우
데이터 종속이란? : 한 데이터를 한 응용프로그램에서만 사용할 수 있다면 그 데이터는 그 응용프로그램에 종속 되어 있는 것
데이터 무결성(Integrity)유지 : 데이터 베이스가 바른 상태에 있는 것을 뜻함
ex) key : 유일성(값이 같으면 안됨, Null값은 안됨) referential integrity(참조 무결성) : 한 테이블에서 다른 테이블값을 참조 할때 참조 하는 테이블의 값이 없을 경우 참조하는 테이블이 없는 값을 참조하게 되는 경우가 생김, 이 경우를 방지하는 것이 참조 무결성이다.
* 파일시스템과 데이터 시스템 비교 표
| 특성 | 파일시스템 | 데이터베이스 |
| 데이터의 구조 | 특정 구조로 저장되어 관리되지 않음 (Raw data) |
Table 형태로 구조화 되어 저장됨 |
| 데이터 접근방식 및 작업 | 데이터를 찾기 위해서 순차적으로 데이터 접근 데이터 연결은 응용프로그램에서 진 순차적으로 저장된 파일들을 액세스 응용프로그램마다 각각 다른 데이터 저장 데이터 공유 어려움 데이터 접근하기 어려움 데이터 표준 정립이 어려움 |
비순차적 접근(random access) 가능 SQL 쿼리 를 사용해서 값을 빠르게 찾음 Random read/write가 모두 가능 테이블 형태로 데이터가 저장 데이터 공유(Sharing)가 가능함. |
| 데이터 중복과 불일치 | 각각 응용프로그램의 데이터타입에 맞춤 동일한 의미의 데이터가 중복되어 저장 이 경우, 데이터의 불일치가 일어날 수 있음 데이터 공간 낭비가 발생 |
데이터 *스키마 전체를 가지고 있으므로 응용 프로그램은 필요한 정보를 사용. 데이터가 여러 곳에 중복되어 저장 X 데이터 수정 용이 데이터 중복제어 (중복되면 불일치 문제 발생 할 수 있음) |
| 데이터 무결성 제약조건 | 데이터 무결성을 보장하기 어려움 | 데이터 *무결성 유지 - Consistency |
| 데이터 독립성 | 데이터가 종속적 | 데이터가 독립 |
| 보안 | 각 프로그램마다 데이터를 각각 가지고 있기 때문에 여러 경로로 데이터의 접근이 가능 즉, 보안이 어려움 |
데이터를 한 곳에서 관리 허가한 사람에게만 데이터베이스 들어갈 수 있도록 함 데이터베이스 내에서도 열람 가능한 권한을 다르게 부여함 즉, 보안이 강력함 |
* 스키마 : 관계형 데이터베이스에서 데이터가 구조화되는 방식을 정의
* 데이터 무결성이란 데이터의 Lifecycle 동안 모든 데이터가 얼마나 완전하고, 일관되며, 정확한지를 나타내는 정도
* 데이터형태 : 정형, 반정형, 비정형
* 데이터모델 : 데이터와 데이터 사이의 관계 그리고 무결성 제약을 기술하기 위한 개념적인 도구의 모임을 뜻한다.
발전 순서 : Network -> Hierarchical -> Relational -> Object-oriented -> ER(DataBase를 옮겨 다녀야 되는 현재 모델에서 먼저 만듦, 이후에 Relational로 바꿈, 왜 이렇게 하냐면 사용자의 요구를 받아들이기 위해 생긴 것, 개발자들끼리 의사소통을 하기 위한 것)
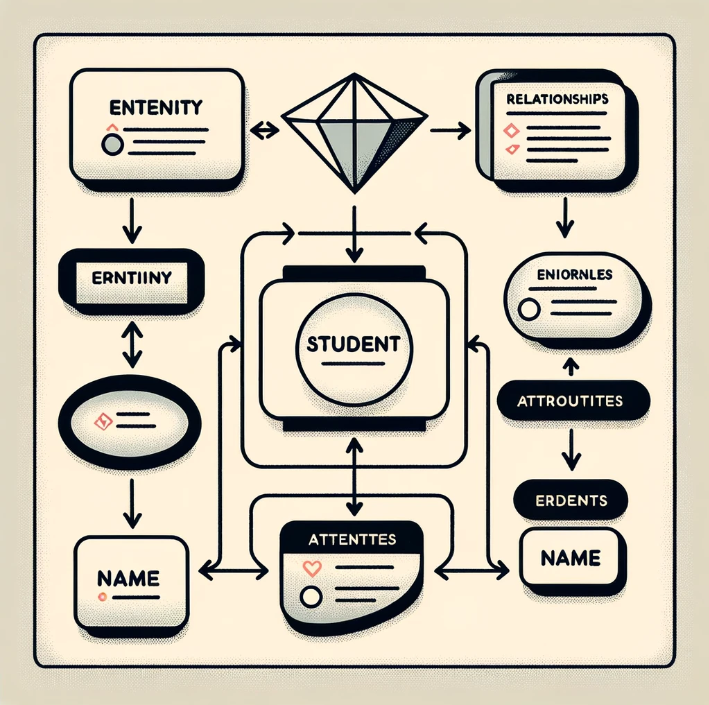
1) ER 다이어그램
: E -Entity (개체), R - Relationship (관련성), Attribute(속성)의 관계를 나타낸 다이어그램
2) 계층(Hierarchical) 데이터베이스
: 트리모델(루트와, 차일드, 노드, 링크)
: null 루트를 만드는 이유는 트리는 루트로부터 검색을 시작하기 때문에 null값 루트도 넣는 것
: 중복되는 값들로 인해 불일치가 생겨버림, 그런 것은 포인트를 사용해서 방지함
3) Network 데이터베이스
: N대 M관계, 속도가 느림

4) 관계(Relational) 데이터베이스
: 객체지향 데이터 모델
: 테이블 형태로 바뀜, 넘버가 생김
: 처음에는 속도가 느려서 안 사용하다가 지금은 관계모델로 사용함

* 데이터베이스 시스템
: 응용 프로그램 또는 쿼리 <-> DBMS : 쿼리와 응용 프로그램 처리를 위한 소프트웨어, 저장되어 있는 데이터베이스 접근을 위한 소프트 웨어 <-> 데이터 베이스와 Metadata
- 쿼리 : 데이터베이스에 사용자가 요청한 특정 데이터를 보여달라는 요청
| 학번 (도메인) (속성,Attribute) |
이름 (도메인) (속성) | 주소 (도메인) (속성) | 성별 (도메인) (속성) |
| 20222 (튜플) | 홍길동 | 대전시 | 남 |
| 20233 (튜플) | 유관순 | 광주시 | 여 |
| 20334 (튜플) | 우지후 | 인천시 | 남 |

속성(Attribute) : 데이터베이스를 구성하는 가장 작은 논리적 단위, 파일 구조상의 데이터 항목 또는 데이터 필드 해(열)
속성은 도메인을 가질 수 있다.
ex) 저 테이블에서 학생의 Attribute는 학번, 이름, 전공, 전화번호이다.
도메인(Domain) : 각각의 속성들이 자신이 가질 수 있는 값들의 집합
튜플(Tuple) : 하나의 DATA, 속성의 모임으로 구성, 파일 시스템에서 레코드와 같은 의미 (행)
-> Tuple 6개(Set of 6 Tuples)가 모이면 Cardinality라고 부른다.
* 데이터베이스 내부구조
- 실제 Data가 구성될 때는 우리가 원하는 Data를 빠르게 찾아야 함 -> Indexing과 Hashing 기법을 사용한다.
- DBMS가 B Tree를 제공한다.
- Indexing : key값을 추가하며 찾는다(?)
- Hashing : key값으로 주소를 산출 // 주어진 키 값을 이용하여 목표 레코드 주소를 직접적으로 계산하는 방법
B+ TREE 구조
1) Index구조, Data를 빨리 찾는방법이다.2) Sequance Set(Acess)이 있다. : 우리가 어떤 데이터를 찾고나서 그 데이터로 부터 연속해서 데이터를 찾고 싶은 경우튜플 -> 튜플을 가르키는 포인터가 있다.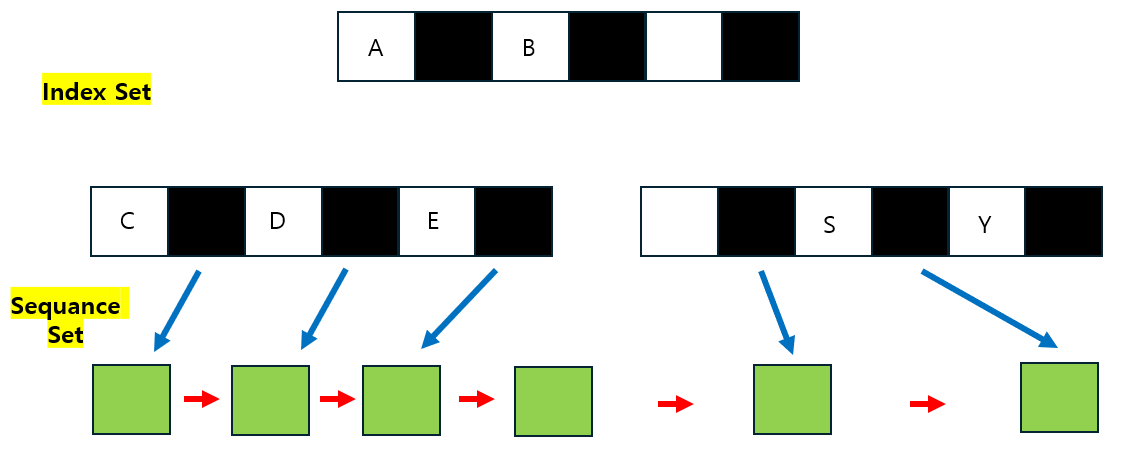
'데이터베이스 관리론' 카테고리의 다른 글
| [데이터베이스 관리론] 데이터베이스 관리 (0) | 2024.06.15 |
|---|---|
| [데이터베이스 관리론] 관계 데이터 모델 (0) | 2024.04.22 |
| [데이터베이스 관리론] 정규화에 관하여 (2) | 2024.04.01 |
| [데이터베이스 관리론] ER Modeling (0) | 2024.03.17 |
| [데이터베이스 관리론] 데이터 추상화(abstraction)와 DBMS/사용자 그리고 데이터베이스 시스템 개발 단계 (0) | 2024.03.16 |



